
SEC Cyber Incident Materiality Disclosure Rule
This isn’t a massive change; this is a massive chance to help your organization define a process that establishes cybersecurity as a business partner and for us to show the business leaders in our orgs that we are prepared to truly be partners.

Leadership Culture
Ultimately my role as a leader is to ensure that teams have the tools and expectations they need to do their job and to remove roadblocks preventing them from being successful.

Responding To Ransomware - A Pragmatic Guide
There is no one size fits all for ransomware response, but there are some universal concepts that I have seen work effectively.
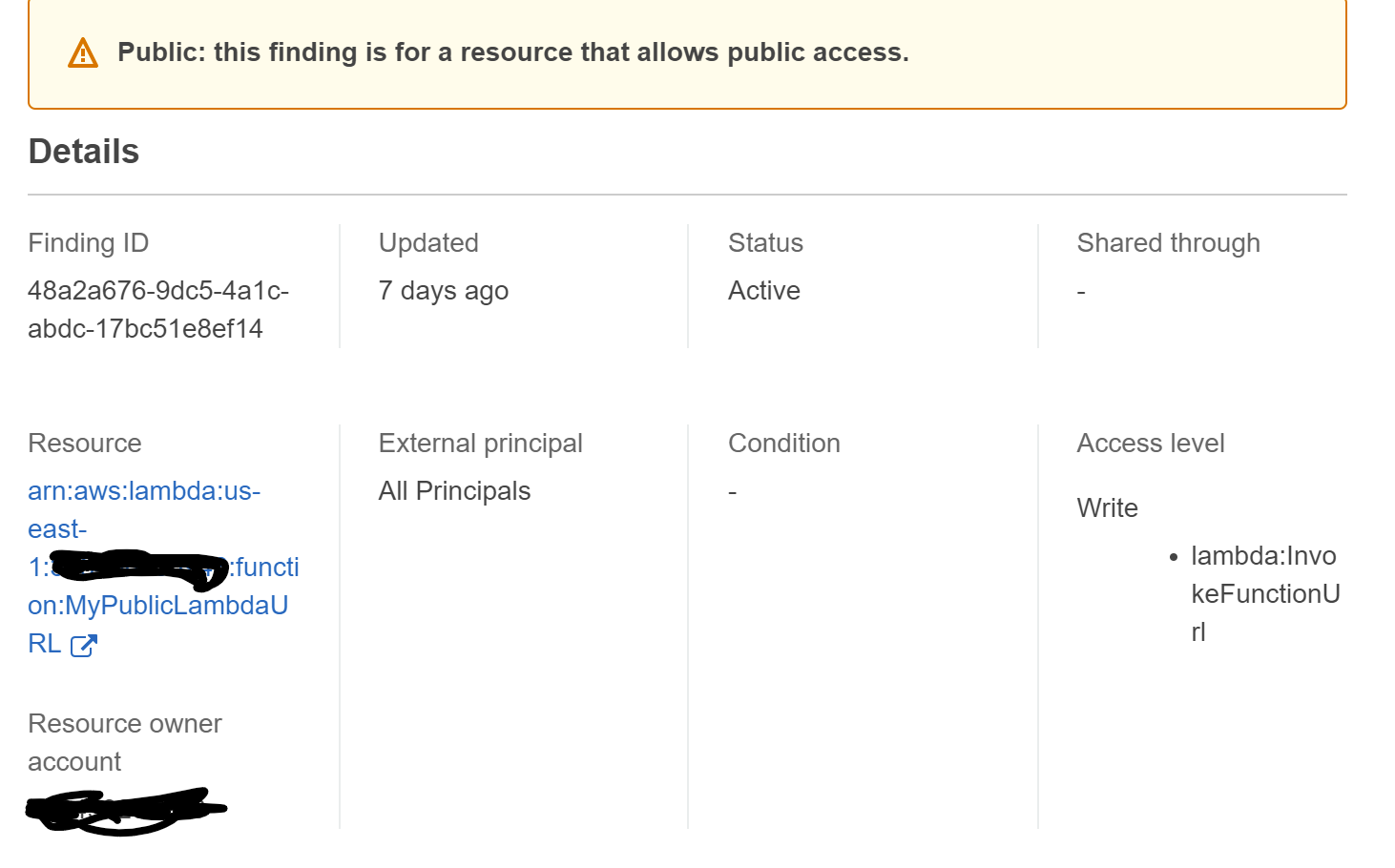
AWS Lambda Function URL
What should we do about this new feature in Lambda? Allow it? Prevent it?

Identity Theft - It Happened To Me
My account of identify theft and steps I took before and after.

Am I Secure From Ransomware?
Are you protected from ransomware? How can you tell? If you wanted to know your ransomware risk, what would you look for?
Log4Shell / Log4j Explained - Details and References
Everything you need to know about Log4Shell
New Job, Pandemic, Fully Remote
The bottom line is this. Starting at a new organization remotely is not hard, but to do it well takes effort.
Be purposeful and genuine in conversation.
Use “I” a lot less.
Ask lots of questions
Get to know people. For real.
Show your face. Use quality tech.



